Data Harmonization
Global health and development data span many years and many countries and communities, and each study results in a unique set of data. At Ki, we not only guide partners, internal teams at the Bill & Melinda Gates Foundation, and foundation grantees through the research process, but we also facilitate their efforts to answer complex research questions by pooling data from multiple studies. Since 2014, we have worked with data contributors all over the world to advance data sharing for secondary analysis.
Data pooling and data reuse for secondary analysis, when appropriate, can save researchers a great deal of time, effort, and money by avoiding duplicative data collection and thus speeding up the search for answers to complex research questions. This translates to more lives saved, more livelihoods improved, and more problems solved—and more quickly. But individual studies collect data using different methods, and data gaps can result when certain variables are not collected from study participants due to time or resource constraints. That’s where data harmonization comes in.
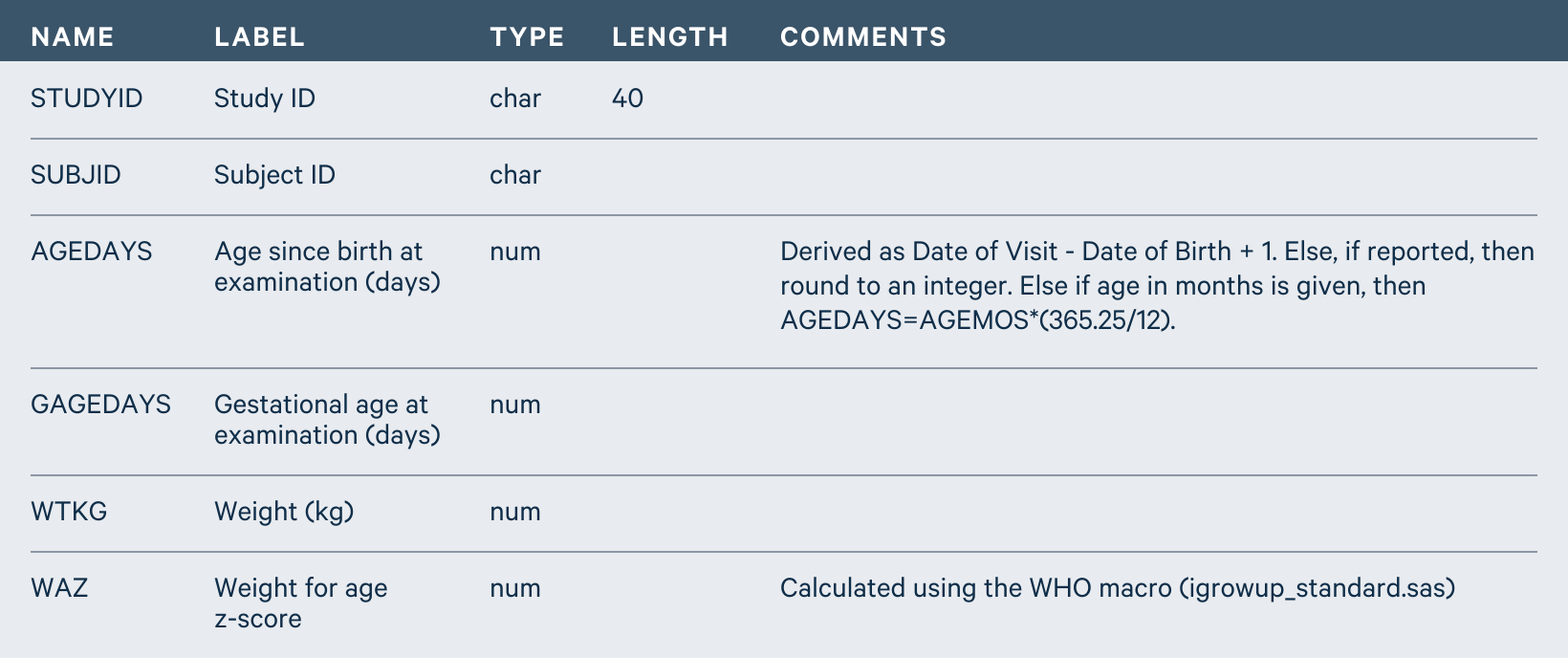
At Ki, we curate and harmonize data to a common standard. This is critical to turning existing data into reusable assets. Given that different studies collect and maintain data in different formats, we maintain standard metadata across all studies in the Ki database to help users understand the data better. (Metadata are terms that describe the data collected; this “data about the data” can include variable names, labels, formats, and basic statistics about all variables in a study, for example. See the example below.) We strive to follow the widely accepted FAIR (Findable, Accessible, Interoperable, and Reusable) data principles for open-access research data. (Go to our Data Store Explorer tool to see visualizations of metadata in the Ki data repository, which encompasses more than 150 studies related to global health and development, mostly from low- and middle-income countries.).
Data Standards
Creating a high-quality pooled data set involves careful programming and data cleaning by data programmers. This is crucial for data reuse because, as all researchers know, the “garbage in, garbage out” principle applies—poor-quality input leads to unreliable results. Several data standards and data models exist for different types of data. At Ki, we have developed our own data standard to account for the less regular structure of global health studies and to be able to harmonize across the studies to generate queryable data sets for analysis. Our data standard is a modified version of the global Study Data Tabulation Model (SDTM) standard from the Clinical Data Interchange Standards Consortium (CDISC), which is used by the U.S. Food and Drug Administration and the pharmaceutical industry.
Data standards enable the creation of standardized code, reusable macros, and other templates, thereby enhancing the reusability of data, simplifying data management, and speeding up data analysis by reducing cycle times. We provide extensive documentation of these standards to all partners and grantees. We also give them access to the Ki data harmonization process, our metadata, and reusable code. Anyone is free to adapt this data model for their own use. Starting with this data model can save principal investigators a significant amount of time and effort, particularly during the data collection and protocol development phases. We also generate the pooled data sets in easily shareable and usable data formats, such as CSV files.
We believe that data sharing for secondary analysis not only leads to greater impact in global health and development, but it also allows researchers and institutions in the low- and middle-income countries and communities where data are collected to reap the benefits in their own research efforts and initiatives. For too long, they have faced inequities in access to data—as well as access to state-of-the-art data processing software and code. Our efforts serve the larger goals of seeing research data made available to the entire community of global health and development researchers in near-real-time and of promoting data sharing principles far beyond Ki.
Legal agreements for data sharing
As data privacy laws around the world continue to evolve in patchwork fashion, with the European Union leading the way in setting comprehensive legislation governing the collection and use of personal data and the movement of data, it is critical to have a legal basis for acquiring research data for secondary analyses. We believe that the use of data to improve lives should never come at the expense of the privacy and trust of the people who share their information for the benefit of others. This means setting conditions and expectations for partners to access the data. Ki employs two types of legal agreements that govern data sharing: the Data Contributor Agreement, which allows a data generator to contribute data for secondary use, and the Data Access Agreement, which enables partners to access Ki data under set conditions for data use.
We believe in both data sharing and data privacy. For more on our data privacy approach, read Sharing Data and Privacy – Both/And.